
The W3C specification defines XML as a subset of SGML, so to properly understand XML, it is wise to take a closer look at SGML first. ### need to add some SGML background info here ### The reason why XML seems to be so similar to HTML lies in the fact that HTML is definied as an application of SGML. So XML is actually a lot more similar to SGML than to HTML, because HTML is only one specific application of SGML used to describe web pages. As XML was created to simplify SGML, it is no wonder that the W3C has now moved ahead to redefine HTML 4.0 as an XML application, thereby creating XHTML 1.0. But this shall be of no concern for us at the moment, because we are still faced with the fundamental question "What is XML?". To answer this, let me tell you upfront what XML is not:
XML simply is a clearly defined way to structure, describe, and interchange data. And by data I really mean every conceivable kind of data! You can use XML for such diverse things as describing mathematical formulas, chemical compounds, astronomical information, finanical derivatives, architectural blueprints, annotating Shakespearean plays, collecting Buddhist wisdoms, or voice-processing in telephone systems. To get a feeling for XML, it is perhaps useful to take a look at a simple XML document as a starting point:
The < and > brackets are used to distinguish between the so-called "markup" (between the brackets) and the actual data of the document (outside of the brackets). The XML document is said to consist of individual elements that are marked by start- and end-tags (hence the term markup), that contain the name of the element so that they can be distinguished from one another more easily. The start-tag is bracketed by < > and the end-tag is enclosed by </ > - both the start- and end-tag must always occur in pairs. Hence the above XML document contains one element called "product", which consists of two elements: "name" (which contains the data "Apple") and "price" (which contains the data "0.10"). Contrary to HTML, XML does not enforce a predefined set of allowed element names (such as "body", "h1", and "p") - you can make up your own to suit the particular needs of your data. This simple XML document also shows a very important aspect of XML - it is "self-describing". In addition to structuring the actual data, the XML element names (sometimes also called tag names) serve to describe the information provided in this document (in our case obviously the price of an Apple). If you compare this to the way such data is traditionally exchanged between different applications (e.g. comma-separate value or CSV files), you can easily see the benefit:
This is even more obvious, if you look at a slightly more complicated XML example document (as shown as in the Text View of XML Spy):
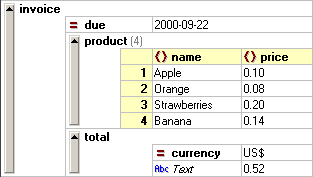
You can immediately see another crucial property of XML here: the elements can be nested in any way that is useful to show the semantic structure of the data contained, and elements can be repeated, if more than one item of data of the same kind needs to be listed. Our example now describes an invoice with two products and a total. Also, you will note that some elements now contain additional information within the start-tag: these so-called attributes always have a name and a value and are written as name="value". They are used to further specify additional information that augments the data of the element (in our example, the currency of the total). Another thing that you will see, is that the bigger an XML document is, the more markup it contains and consequently it can become rather difficult to find the actual data contained therein. This slight disadvantage is typically more than compensated by the flexibility of XML and by the fact that XML is inherently suitable for reading by both humans and machines. However, when you are viewing or editing XML documents as a human being, most of the time you tend to wish for a better way to see and manipulate XML data. This is why XML Spy offers you a more concise presentation of any XML document - called the Enhanced Grid View - that lets you immediately see important aspects of your document, such as the actual data contained:
This is the same XML document as above, but this time it is immediately obvious that there are 4 products on this invoice and their names and respective price are shown as columns of a table - just like you would expect to see that data. Furthermore, editing in this view is infinitely more comfortable, since you can simply drag & drop elements, insert new rows, copy/paste your data to and from other applications (e.g. Excel, Access, etc.), and manipulate it in a graphical way that is not possible in views offered by other products. Even though we haven't touched the more advanced aspects of XML yet, you now have a first impression of an XML document and have learned about the two most important features of XML: elements and attributes. We will proceed to explain the other concepts of XML further on in this tutorial when we look at the various features that XML Spy provides you with. Before we continue to do that, let us first consider the ever-important "why" question... |
© 2000 Altova |